A Framework for Deployment of Immutable Infrastructure
Nov 26, 2015 using tags aws, terraform 9minIt’s been a little over eight months now since we (at FreshBooks) first dipped our toes into AWS, and boy has it been a wild ride! We’ve come a very long way since that first month where my team experimented with re-building a portion of FreshBooks using a modern stack (Docker, CoreOS, Fleet, Consul, etc).
But I’m going to save all that fun stuff for another blog post! Today I’m going to present an idea my team explored to make pieces of our internal infrastructure more resilient to underlying resource contraints (and also easier to manage).
This is our journey towards Anti-Fragility.
The Old Days
Let’s start with what things looked like.
In addition to production, our Operations team at FreshBooks also maintains a few services we lovingly refer to as “Office Services”. Some examples are JIRA, Github Enterprise, Request Tracker (support requests from customers), you get the idea. These are the things that are primarily consumed by internal employees.
We’ve traditionally hosted these services in the server room at our lovely Toronto office because it was the cheapest and quickest way to keep these things firewalled from the Internet. And because ESX has been something that was easily accessible to us.
The Problems
A plethora of things can and do go wrong with physical hardware and unfortunately all the configuration management in the world isn’t going to make this better. The more $$$ you pay, the more options you have in terms of automatic failovers and all that but frankly the added complexity (and $$$) was just not worth it. You inevitably end up with a single point of failure and other related sadness, which leads to my next point.
Recovering from catastrophes in this ecosystem becomes somewhat of a black art. You end up spending a lot of peoples’ very expensive time bringing these machines back from the brink of death.
There is Hope
Let’s take a trip back to the AWS experimentation phase for a second. One of the concrete things that came out of it was that my team (the dev-tools team at FreshBooks) moved all our Jenkins build workers from Rackspace/ESX to AWS (where they’ve happily been ever since!). In order to get this move done, we needed to build a site-to-site VPN from our office to the VPC we use in AWS (in order to handle private routing).
Where does this leave us.
- Network firewalled from the Internet ✔️
- Spin up nodes quickly and programmatically ✔️
- Recover from a catastrophe with minimal intervention ❓
We weren’t sure about that last one just yet.
The Opportunity
We were tasked by our manager to upgrade our instance of Github Enterprise (GHE). Knowing what we knew and given the experience we had with AWS, we took the opportunity to move our GHE instance to AWS. For the most part, Github makes this relatively easy to do. They have built a bunch of tools and written some excellent documentation and this made our lives immensely easier!
We wanted to do better though. Given that nodes in AWS can (and will!) go away in a moments notice, our GHE instance had to meet at least the following requirements:
- It should recover from known AWS failure scenarios
- It should never lose our data
- It should be trivial to bring back to a known working state
The Workflow
At FreshBooks, we very much heart the Pull Request workflow. We use it for all our applications and it is something that everyone is especially familiar with. We decided that there was no reason this system had to be different.
Our proposed workflow looked something like:
- A person submits a Pull Request to change something
- Other people code-review said Pull Request
- Upon merge to master, robots take over and do all the work
The Design
If you’re thinking this is ambitious and probably overkill for a Github Enterprise upgrade, you are not wrong! But do also keep in mind we used this project as an opportunity to experiment and see if any of these ideas carried over to other (similar) types of infrastructure
Considering that we were aiming for an entirely Pull Request based workflow and that we were already fairly comfortable with Terraform, we felt like like Terraform and Atlas were good choices here.
And that satisfied all our workflow requirements!
The Details
Let’s recap. At this point we have a basic set of requirements and also a workflow we like. Now for the implementation details!
Going back to GHE specifics for a second – one of the lovely advantages of hosting a GHE instance on AWS is that Github already provides you with a pre-baked AMIs that are ready to go! This certainly makes life a whole lot easier.
Translating this to Terraform speak looked something like:
resource "aws_instance" "ghe_node" {
ami = "ami-347c015e"
instance_type = "m4.xlarge"
subnet_id = "<subnet_id>"
vpc_security_group_ids = ["<security_groups>"]
associate_public_ip_address = 1
private_ip = "192.168.100.5"
tags {
Name = "github-enterprise"
}
}
resource "aws_ebs_volume" "ghe_vol" {
availability_zone = "us-east-1"
size = 100
tags {
Name = "github-enterprise"
}
snapshot_id = ""
}
resource "aws_volume_attachment" "ghe_vol_att" {
device_name = "/dev/xvdf"
volume_id = "${aws_ebs_volume.ghe_vol.id}"
instance_id = "${aws_instance.ghe_node.id}"
}This little terraform snippet stands up a GHE node in a VPC and assigns it the
the private IP address of 192.168.100.5. It also attaches a 100GB external
EBS volume to the EC2 instance (which GHE uses as the data volume).
Simple enough. This keeps the data volume separate from the EC2 instance so instance terminations don’t affect the data volume. Great, let’s move on to outage scenarios.
Failure Scenarios
“For the majority of the cases below, manually triggering a Terraform run will (and should!) wire things back into a working state.”
– An excerpt from our service recovery playbook
To review, the intention behind (the design of) this system was to make it easy enough for humans to operate. A person woken up at 3am should not be made to poke around the AWS interface to figure out which EBS volumes belong to which node and start manually putting things together.
Given that, here are the failure modes we envisioned:
The Github Enterprise EC2 instance has been terminated (accidentally or otherwise) – solution: Trigger a Terraform run
We need to revert to an older Github Enterprise snapshot – solution:PR the snapshot ID and merge to master (which will trigger a Terraform run)
We need to recycle our GHE EC2 instance – solution: Terminate the EC2 instance and trigger a Terraform run
What Terraform essentially does is that when it notices that a resource it was
tracking went away, it will create a new resource to take its place and wire
things back up correctly. This is partially where that private IP address of
192.168.100.5 comes into play. Whenever Terraform brings up a new EC2 node,
it will always assign it that IP address. Which means that DNS records don’t
need to change. Similar concept for re-attaching an EBS volume to a newly
spun up EC2 instance.
Atlas Workflow
The last piece of this puzzle is Atlas. Atlas gets us the ability to automatically trigger Terraform runs via Github hooks, with the option of allowing a human to approve a change.
After a Pull Request gets submitted, Atlas kicks off a
terraform plan(dry run) and updates the Github build status.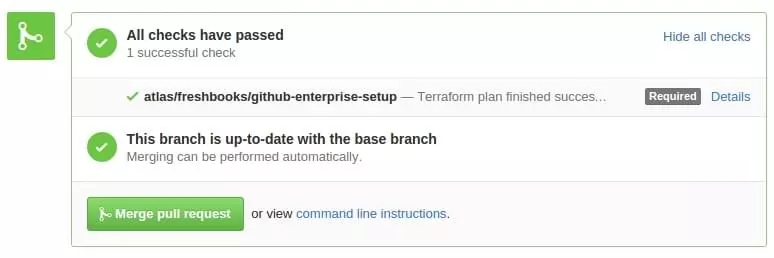
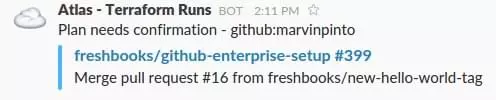
After the PR gets merged, Atlas kicks off another Terraform run which notifies us in Slack and prompts us to approve this change.
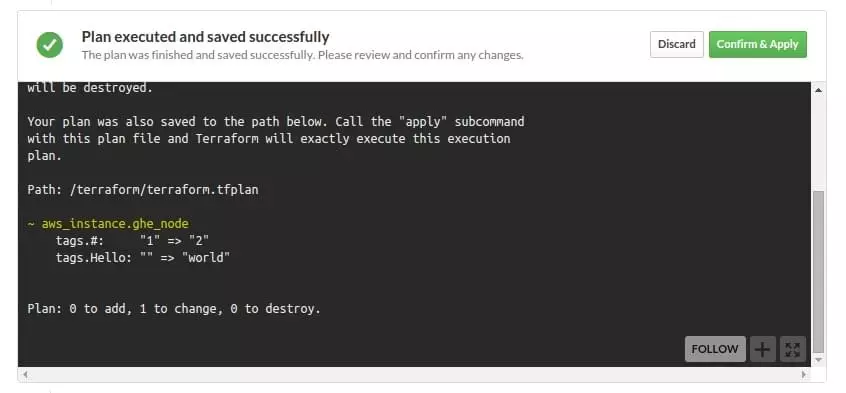
In the Atlas interface, it’s easy to see exactly what will happen once a change gets approved.
Hitting the Confirm & Apply button kicks off another Terraform run that goes and makes the required changes (and then notifies us in Slack)
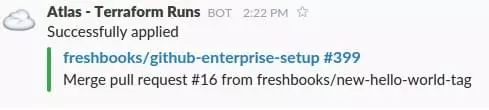
And that’s it! There are enough checks and guards in this workflow and yet lightweight enough that this works.
Given all that, let’s recap where we are at:
- Network firewalled from the Internet ✔️
- Spin up nodes quickly and programmatically ✔️
- Recover from a catastrophe with minimal intervention ✔️
Some other things we considered
Manually spinning this up in AWS - the obvious downside here is reproducibility and would involve a person manually having to bring this back if it ever went away. This would not work for us.
Autoscaling group of one - This one was hard to do with GHE. Needing to attach the previous EBS volume to a newly spun up node is not trivial and was not worth pursuing.
Sometimes there are situations where you really don’t want (or need!) autoscaling groups for certain services. A self hosted JIRA or Confluence are good examples here. You generally want the thing up and running and if/when it goes down, you want to bring it back to the state it was in previously with a minimal amount of fuss.
Using Ansible/something else to stand all this up - Simplicity was the key here. It was much easier to get this done in Terraform and the added benefit of Atlas for maintaining state and taking care of deployments was a no-brainer. It is really nice that Terraform makes sure that all the CloudWatch alarms and other things get assigned to whatever node it brings up.
How would this apply elsewhere
A system like this would be ideal to stand up services with a similar operational signature, specifically:
- No real need for HA
- Datastore can be kept separately
A high level plan would look something like this:
- Create a base AMI of your service using Packer
- Ensure that your service (image) is configured to use a separate data volume
- Create a Terraform playbook to stand this up
One of the lovely upsides of using Packer in a system like this is that Atlas also handles running Packer builds. Which means that it would not be hard to setup an end-to-end Pull Request based deployment solution for rolling out new versions of your services. It’s very exciting!
Conclusion
This model has worked out pretty well for us so far with Github Enterprise. There was a time when we avoided upgrading versions just because it was so tedious to do in a VSphere/ESX environment.
Being able to easily test upgrades & downgrades becomes very important because it removes that one more barrier, which in the end leads to event free deploys!
The banner for this post was originally created by Boba Jovanovic and licensed under CC0 (via unsplash)